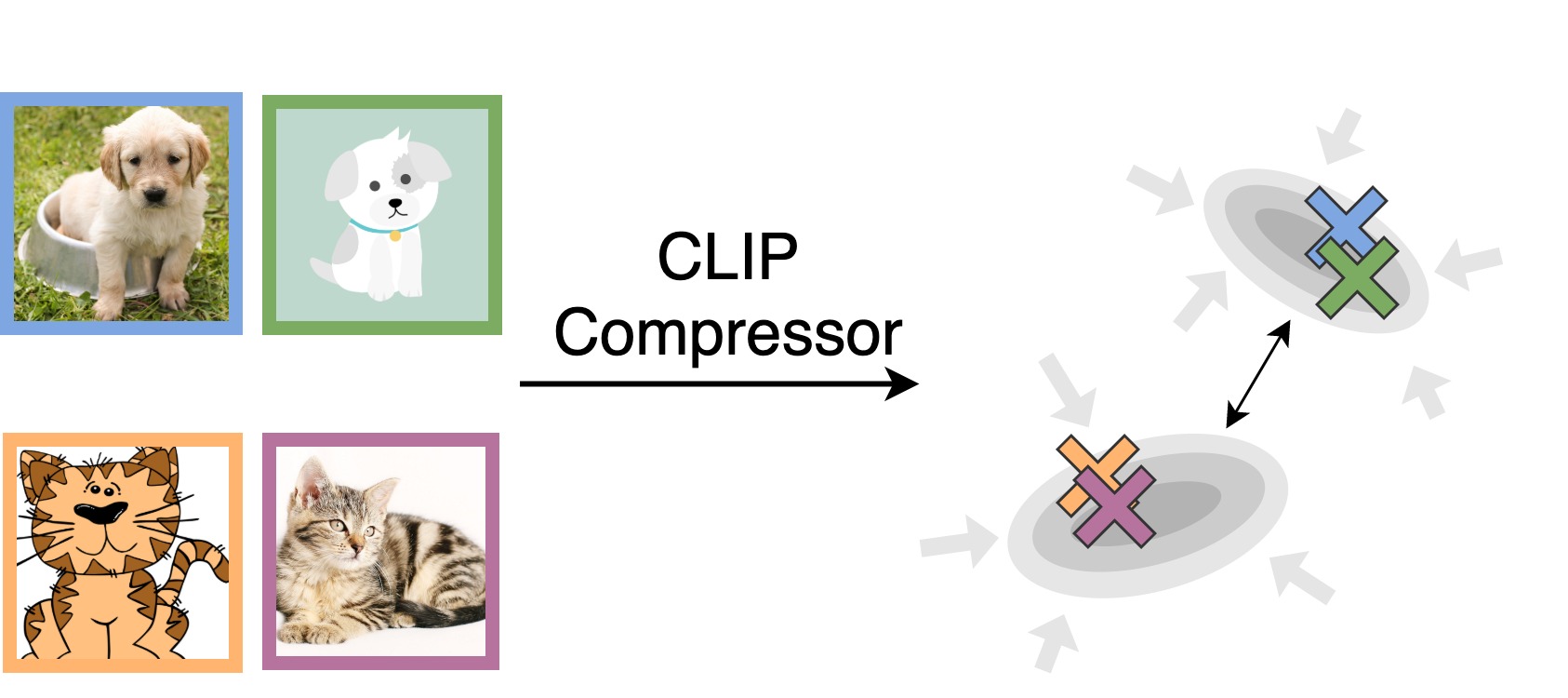

Model Description
CLIP Lossyless compressor from is a generic image compressor that only retains the parts of the image that are necessary for classification. This can work on any dataset (standard images, people, biological tissues, satellite images,…) and the compression gains are larger if the images are larger. For ImageNet it gives >1000x compression gains compared to JPEG. The output of the compressor is a vector representation of the image (nto an image), which allows downstream classification to be done using a simple linear classifier.
Dependencies
CLIP compressor depends on CLIP and compressai. Install with
pip install torch torchvision tqdm numpy
pip install compressai git+https://github.com/openai/CLIP.git
Getting the model
Load the compressor and the transformation that should be applied to an image before compression (resizing + normalization).
import torch
# Load the desired compressor and transformation to apply to images (by default on GPU if available)
compressor, transform = torch.hub.load(
"YannDubs/lossyless:main", "clip_compressor_b005"
)
Example usage: compressing a dataset
We will show in this example how to compress an entire torchvision to disk. Now that the model is downloaded we need a dataset. Note that we apply the desired transformation.
from torchvision.datasets import STL10
DATA_DIR = "data/"
# Load some data to compress and apply transformation
stl10_train = STL10(DATA_DIR, download=True, split="train", transform=transform)
stl10_test = STL10(DATA_DIR, download=True, split="test", transform=transform)
Now we compress the dataset and save it to disk. This requires a GPU.
# Rate: 1506.50 bits/img | Encoding: 347.82 img/sec
compressor.compress_dataset(
stl10_train,
f"{DATA_DIR}/stl10_train_Z.bin",
label_file=f"{DATA_DIR}/stl10_train_Y.npy",
)
compressor.compress_dataset(
stl10_test,
f"{DATA_DIR}/stl10_test_Z.bin",
label_file=f"{DATA_DIR}/stl10_test_Y.npy",
)
The dataset is now saved to disk, in less than a MB!
du -sh data/stl10_train_Z.bin
Let us now load and decompress the dataset from file. The decompressed data is loaded as numpy array.
# Decoding: 1062.38 img/sec
Z_train, Y_train = compressor.decompress_dataset(
f"{DATA_DIR}/stl10_train_Z.bin", label_file=f"{DATA_DIR}/stl10_train_Y.npy"
)
Z_test, Y_test = compressor.decompress_dataset(
f"{DATA_DIR}/stl10_test_Z.bin", label_file=f"{DATA_DIR}/stl10_test_Y.npy"
)
Let us show that all information needed for classification is retained. We will fit a simple linear classifier (SKlearn required).
pip install sklearn
from sklearn.svm import LinearSVC
import time
# Accuracy: 98.65% | Training time: 0.5 sec
clf = LinearSVC(C=7e-3)
start = time.time()
clf.fit(Z_train, Y_train)
delta_time = time.time() - start
acc = clf.score(Z_test, Y_test)
print(
f"Downstream STL10 accuracy: {acc*100:.2f}%. \t Training time: {delta_time:.1f} "
)
References
You can read the full paper here. Please cite our paper if you use our model:
@inproceedings{
dubois2021lossy,
title={Lossy Compression for Lossless Prediction},
author={Yann Dubois and Benjamin Bloem-Reddy and Karen Ullrich and Chris J. Maddison},
booktitle={Neural Compression: From Information Theory to Applications -- Workshop @ ICLR 2021},
year={2021},
url={https://arxiv.org/abs/2106.10800}
}
